The max_wal_size parameter in PostgreSQL is a critical setting that directly impacts the Write-Ahead Log (WAL) system, influencing both write performance and recovery time.
It controls the maximum amount of WAL data that can accumulate before a checkpoint is triggered, helping to manage disk I/O and recovery behavior.
In this article, we’ll explore how max_wal_size works, its performance implications, and how to configure it effectively to meet your system’s needs.

Get Your Free Linux training!
Thank you very much for visiting our website! We’re creating a comprehensive Linux training course! 🚀 If you're interested, just enter your email address, and we'll send it your way. It is free today. Hope it helps you level up your skills and accelerate your career! 🔥 Have a Nice day!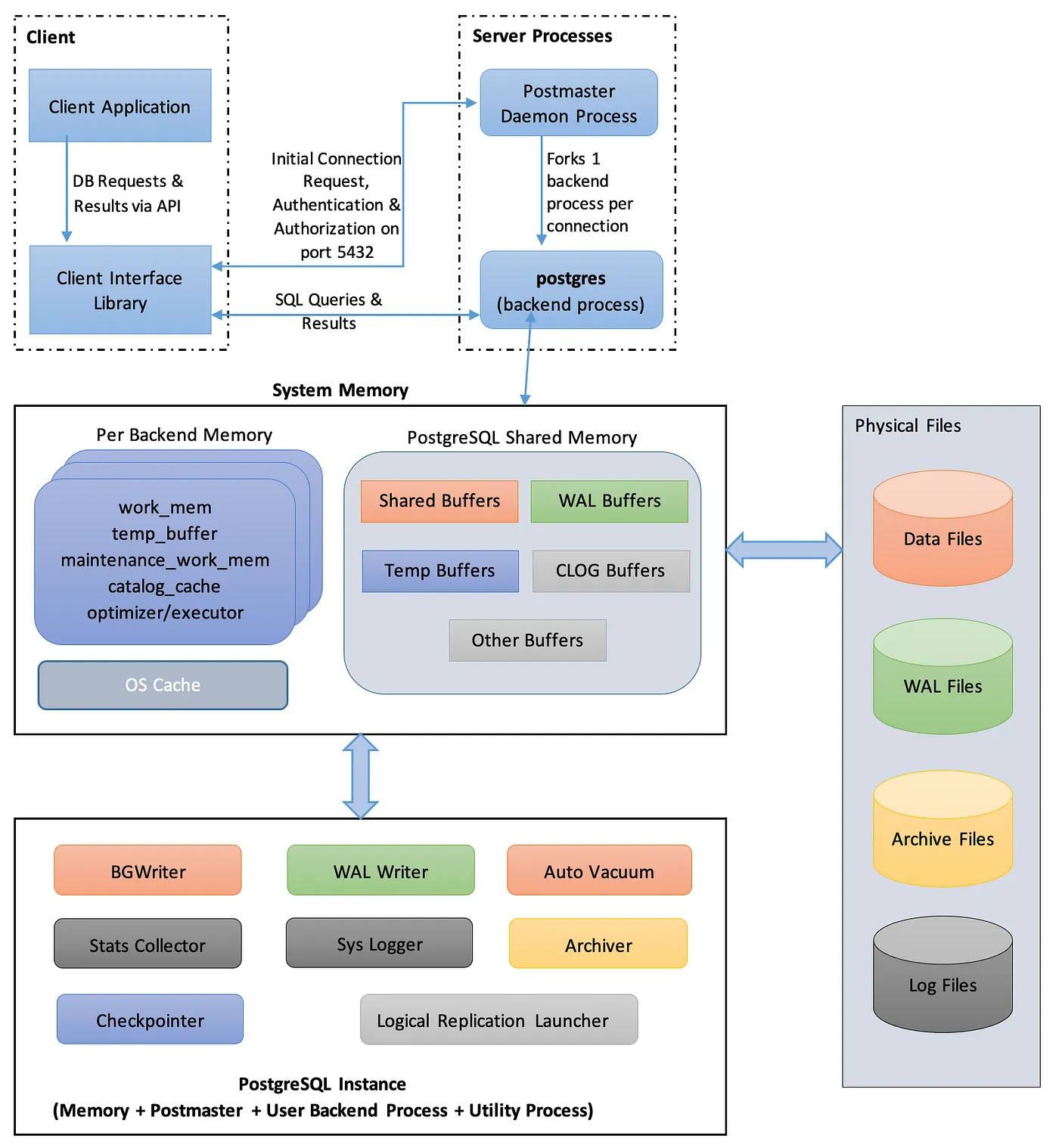
Table of Contents
Understanding max_wal_size
PostgreSQL uses Write-Ahead Logs (WAL) to ensure data integrity by logging all changes made to the database before they are written to the data files.
The checkpoint process is an important mechanism that helps to ensure data durability by flushing changes from the WAL to the disk. The max_wal_size parameter determines how much WAL data can be written before PostgreSQL triggers a checkpoint.
Here’s a breakdown of the key aspects of max_wal_size:
1. Purpose of max_wal_size
- Controls WAL Accumulation: The
max_wal_sizeparameter sets the maximum limit for the accumulation of WAL data before PostgreSQL performs a checkpoint. When the total amount of WAL data exceeds this limit, the system will automatically trigger a checkpoint. - Checkpoint Behavior: A checkpoint in PostgreSQL ensures that all data modifications made in memory are written to disk. During this process, the database ensures that the changes are durable and available for recovery in case of a crash.
2. Performance Impact of max_wal_size
Higher Values:
- Reduced Checkpoint Frequency: Setting a higher value for
max_wal_sizemeans that more WAL data can accumulate before PostgreSQL triggers a checkpoint. This results in fewer checkpoints, reducing the frequency of disk I/O operations related to writing changes to disk. - Improved Write Performance: With fewer checkpoints, PostgreSQL spends less time on disk writes, which can improve write throughput, especially on systems with high write loads.
- Increased Recovery Time: On the downside, a larger
max_wal_sizemeans that more WAL data will need to be processed during recovery after a crash. This can lead to longer recovery times because PostgreSQL will have to replay more WAL records to restore the database to a consistent state.
Lower Values:
- More Frequent Checkpoints: Setting a lower value for
max_wal_sizeforces PostgreSQL to trigger more frequent checkpoints. While this reduces the amount of WAL data that accumulates before each checkpoint, it can increase disk I/O overhead due to the more frequent writing of data to disk. - Reduced Write Performance: Because of the increased number of checkpoints, write performance may be negatively impacted, especially in workloads with frequent data modifications.
- Faster Recovery: The benefit of having more frequent checkpoints is that PostgreSQL can recover from a crash more quickly. Since less WAL data needs to be processed during recovery, recovery times will be faster.
3. Balancing Performance and Recovery
The key to setting the max_wal_size parameter is finding a balance between write performance and recovery time. Here are a few guidelines for deciding the appropriate value:
- For High Write Performance: If your primary concern is maximizing write throughput and you can tolerate longer recovery times, you may opt for a higher
max_wal_size. This reduces the frequency of checkpoints, which is beneficial for write-heavy workloads. - For Fast Recovery: If fast crash recovery is more important than write performance, a lower
max_wal_sizemight be preferable. Frequent checkpoints reduce the amount of WAL data that PostgreSQL needs to process in the event of a crash, thus improving recovery times.
In most cases, the best configuration will depend on the nature of your workload and the recovery requirements of your system.
4. Configuring max_wal_size
The max_wal_size parameter is set in the postgresql.conf configuration file. To adjust it, you would typically add or modify the line in postgresql.conf like this:
max_wal_size = 2GB # Example value, adjust based on your workload and requirements
You can also change this parameter dynamically using the following SQL command:
SET max_wal_size = '2GB';
However, changes to max_wal_size will not take effect until the database is restarted.
5. Relationship with Other Checkpoint Parameters
max_wal_size works in tandem with other checkpoint-related parameters, particularly checkpoint_timeout:
checkpoint_timeout: This parameter defines the maximum time interval between automatic checkpoints. Ifcheckpoint_timeoutis reached, a checkpoint is forced, regardless of how much WAL data has been written.- Combined Behavior: PostgreSQL will trigger a checkpoint when either of the following occurs:
- The amount of WAL data exceeds the value set in
max_wal_size. - The time interval set by
checkpoint_timeoutis reached.
- The amount of WAL data exceeds the value set in
Therefore, both max_wal_size and checkpoint_timeout play a role in determining when a checkpoint occurs. If either condition is met, PostgreSQL will initiate a checkpoint.
6. Monitoring Checkpoints
To monitor the impact of max_wal_size on your system, you can use the pg_stat_bgwriter system view, which provides useful metrics related to the background writer process and checkpoint activity:
SELECT * FROM pg_stat_bgwriter;
This view includes information such as:
- The number of checkpoints completed.
- The amount of WAL data written between checkpoints.
- The frequency of checkpoints and how much data has been flushed.
By monitoring this view, you can assess whether your max_wal_size settings are achieving the desired balance of performance and recovery.
FAQ max_wal_size
Key Concepts:
- Write Ahead Log (WAL):
- WAL is a critical part of PostgreSQL’s transaction mechanism. Changes made to the database are first written to WAL before being committed to the main database files (the heap).
- This ensures durability (the “D” in ACID), as committed transactions can be replayed after a crash to bring the database to a consistent state.
- max_wal_size:
- The
max_wal_sizeparameter defines the maximum size for the WAL storage. Once this threshold is reached, PostgreSQL forces a checkpoint to free up WAL space by writing changes to the database. - The main aim of tuning
max_wal_sizeis to manage the frequency of requested checkpoints. Frequent requested checkpoints can negatively impact performance, especially on systems with slower I/O (e.g., magnetic disks or constrained virtual machines).
- The
- Checkpointing:
- Timed Checkpoints: Occur at regular intervals, typically defined by
checkpoint_timeout, and are ideal as they distribute I/O load evenly. - Requested Checkpoints: Triggered when WAL space exceeds the
max_wal_size, and they add unpredictable load, especially detrimental on slower disks. - The goal is to minimize requested checkpoints and maximize timed checkpoints to smooth out I/O operations.
- Timed Checkpoints: Occur at regular intervals, typically defined by
- Tuning Recommendations:
- On systems with high throughput, a larger
max_wal_size(potentially in the tens or hundreds of gigabytes) helps avoid frequent requested checkpoints. - To balance disk space usage and recovery time, consider adjusting
checkpoint_timeout(e.g., setting it to 15 minutes) andcheckpoint_completion_target(e.g., setting it to 0.9 to spread out the I/O load).
- On systems with high throughput, a larger
- Performance Impact:
- Properly tuning
max_wal_sizecan significantly boost performance. On systems with slower disks, optimizing this parameter can lead to 1.5x or even 10x performance improvements in certain benchmarks.
- Properly tuning
- Monitoring:
- You can monitor checkpoint activity using the
pg_stat_bgwriterview, which shows the number of timed and requested checkpoints (checkpoints_timedandcheckpoints_req). - Keeping an eye on these values helps ensure that the system is operating within optimal limits, reducing unnecessary load caused by requested checkpoints.
- You can monitor checkpoint activity using the
Example:
- In a bulk data load scenario on an untuned system, you might see an unusually high number of requested checkpoints, indicating performance issues:
SELECT checkpoints_timed, checkpoints_req FROM pg_stat_bgwriter; checkpoints_timed | checkpoints_req -------------------+----------------- 0 | 188
- Tuning
max_wal_sizeis essential for systems with significant transaction activity, especially those using slower I/O storage like magnetic disks. The goal is to maximize the number of timed checkpoints and minimize requested ones to optimize performance. Proper tuning of this parameter, along with other settings likecheckpoint_timeoutandcheckpoint_completion_target, can lead to substantial performance gains.
This highlights the importance of fine-tuning PostgreSQL’s WAL management parameters for efficient disk space usage and smoother performance.
The max_wal_size parameter in PostgreSQL is a critical setting that affects how often the database performs checkpoints. Checkpoints are like safety points for your database; they ensure that all changes have been saved to disk. The max_wal_size parameter determines the maximum size the Write-Ahead Log (WAL) files can grow before a checkpoint is automatically triggered.
Here’s a breakdown of how max_wal_size works and why it’s important:
- What it does: The
max_wal_sizeparameter sets a limit on the size of the WAL files. When the WAL files get close to this size, a checkpoint is triggered. The default value is 1 GB. - Checkpoints: Checkpoints are essential because they ensure that all data modifications are written to the disk. This involves flushing all changed data pages to disk and writing a checkpoint record in the WAL file. After a checkpoint, older WAL files are no longer needed and can be recycled.
- Recovery: If your database crashes, the recovery process uses the latest checkpoint to determine where to start replaying the WAL to bring the database back to a consistent state.
- Impact of a smaller
max_wal_size: Setting a smaller value formax_wal_sizeresults in more frequent checkpoints. This makes recovery faster after a crash, because there’s less WAL to replay. However, more frequent checkpoints also mean more I/O because the database has to write changes to disk more often. full_page_writes: When thefull_page_writesparameter is set (which is the default), the first change to a data page after each checkpoint causes the entire page to be written to the WAL. This increases the amount of data written to the WAL, partially negating the benefit of smaller checkpoint intervals and causing more disk I/O.- Balancing Act: It is important to balance the need for faster recovery with the performance impact of frequent checkpoints. Setting
max_wal_sizetoo low can degrade performance because of the increased I/O load. - Monitoring: The
checkpoint_warningparameter can be used to monitor checkpoint frequency. If checkpoints occur more often than the set warning interval, a message in the server log suggests increasingmax_wal_size. Occasional warnings are normal but frequent messages mean the checkpoint control parameters should be increased. - Bulk Operations: Large data operations, like copying large amounts of data, may trigger frequent checkpoint warnings if
max_wal_sizeis not set high enough.
Other considerations related to max_wal_size:
- WAL Files: The number of WAL files depends on
min_wal_size,max_wal_size, and how much WAL data is generated between checkpoints. When WAL files are no longer needed, they are either removed or recycled. If the rate of WAL output exceedsmax_wal_size, unneeded files are removed until the system gets back under the limit. - WAL Retention: The most recent WAL files are kept at all times as defined by the
wal_keep_sizeparameter. If WAL archiving is enabled, old WAL files cannot be removed until they are archived. - Restartpoints: In archive recovery or standby mode, restartpoints are similar to checkpoints and can be triggered by a schedule or when WAL size is about to exceed
max_wal_size. However, because of the limitations on when a restartpoint can be performed,max_wal_sizeis often exceeded during recovery. - Peak Growth: If the amount of WAL data grows quickly the
restartpoints_reqcounter on the standby server may show a peak growth as requests to create a new restartpoint cannot be performed immediately. - WAL Buffers: If the system is busy and
full_page_writesis enabled, increasing thewal_buffersparameter can help smooth out response times after each checkpoint.
Adjusting max_wal_size
- Increase If you see checkpoint warnings frequently, it indicates that you may need to increase
max_wal_size. This will reduce the frequency of checkpoints, which can improve performance by reducing I/O. - Decrease: If recovery time is more important than performance, you can reduce
max_wal_size. This will make checkpoints more frequent, speeding up recovery time but increasing I/O.
Summary
In PostgreSQL, the max_wal_size parameter is crucial for controlling the amount of WAL data that can accumulate before a checkpoint is triggered. This parameter directly impacts both write performance and recovery time:
- Higher values improve write performance by reducing checkpoint frequency, but may lead to longer recovery times.
- Lower values increase checkpoint frequency, improving recovery time but potentially reducing write performance.
Configuring max_wal_size requires careful consideration of the workload’s requirements and the desired balance between performance and recovery. Along with other checkpoint-related parameters, max_wal_size plays a central role in the efficient management of PostgreSQL’s Write-Ahead Logging system.
By monitoring the behavior using views like pg_stat_bgwriter, database administrators can fine-tune this setting to meet their system’s performance and reliability needs.